- AI Office Hours
- Posts
- LLMs Aligned! But to what end?
Introduction - Re-aligning Our Expectations of AI
Reinforcement Learning (RL) has become one of the primary engines powering AI alignment, the process of fine-tuning an AI model (usually LLMs) to behave according to a certain set of standards and styles. Reinforcement learning provides the unique ability to instill dimensions of human style and ethics outside of the confines of relatively strict next-token prediction. Reinforcement Learning offers us a chance to supplement traditional fine-tuning methods of prompt-response pairs with a system designed to “nudge” the AI in a direction - funnier, more neutral, more diverse, etc.
Just want code? here you go 🙂 it’s at the bottom of this repo.
To instill these kinds of behaviors into an LLM -let’s say we want the AI to be funnier - that would mean you need to go over all of your training data and make sure that examples are “funny enough” to be considered good training data. But who is deciding what is “funny enough”? What if learning humor comes at the cost of the AI’s primary objective (usually answering questions and carrying conversations)?
My upcoming workshop at ODSC East and this post focuses on Reinforcement Learning from Feedback (RLF) which involves giving an AI iterative feedback on solving a task and letting the LLM adapt its own performance in the hopes of having the AI act in a more expected manner and getting better feedback over time. The most common application of this is in training instruction-following AIs, which is exactly what I will be going over.

Case Study - Teaching a Llama to chat
In a previous post for an ODSC workshop I gave, I showed off results from one of my go-to RLF case studies - fine-tuning a FLAN-T5 model to write more neutral news summaries: https://opendatascience.com/harnessing-llm-alignment-making-ai-more-accessible
In this post I want to show off my second meatier go-to case study - making a conversational chatbot from a raw pre-trained LLM. It’s name is SAWYER - Sinan’s Attempt at Wise Yet Engaging Responses - because I wanted to make a fun name for my LLM too.
That already sounds like an oxymoron doesn't it? - “raw pre-trained” - but what I mean by that is our base model will be Meta’s non chat-aligned LLama 2 model, meaning this model has no ability to answer a question when it comes to us off the shelf.
Our RLF process can be broken down into three steps:
Supervised Fine-Tuning (SFT)
Grab Meta’s 7b non chat model weights: hf.co/meta-llama/Llama-2-7b-hf
Fine-tune the model with several conversations to learn how to convert embedded knowledge into a productive conversation
Reward Training (RT)
Get a dataset of scored responses to a conversational reply, indicating which responses humans preferred
Fine-tune a RoBERTa model to distinguish between preferred and non-preferred responses to a conversation
Reinforcement Learning from Feedback (RLF via PPO)
Obtain an entirely new set of only prompts with the bot response at the end missing
Let the LLM reply to a few and use the reward model to assign rewards to the responses - positive is good, negative is bad
Let the LLM update its parameters, taking into consideration how much reward it got and how far the updated model has deviated from the original weights
The figure below shows the RLF process (the third step) at a very high level:

Our RL loop has SAWYER answering questions, being graded on its performance, and asking it to try again with updated parameters and yes, that image of a llama is AI generated 🙂
The workshop will cover the nitty gritty of how to code all of this but for now let’s skip to the fun part: the results!
The Results
We will see the full suite of results during our workshop but some notable examples stand out. Let’s ask our three versions of SAWYER - no alignment whatsoever (base LLama 2 7b ), only supervised fine tuned (SFT) and fine-tuned plus reinforcement learning from feedback (SFT + RLF).

SAWYER learns to answer questions with SFT, but learns to answer them in a more conversational way with RL
We can see a notable difference between all three stages starting with base non-chat LLama 2 which is trying to write a multiple choice question (I guess?) and our final SAWYER model being the chattiest about the actual answer to the question. That is a relatively cherry picked example but even when we zoom out and test our model against a test set of conversations (done before and after applying RL to our chatbot), plotting for achieved reward scores, our model post RL is on average getting higher preference rewards with a much lower variance:
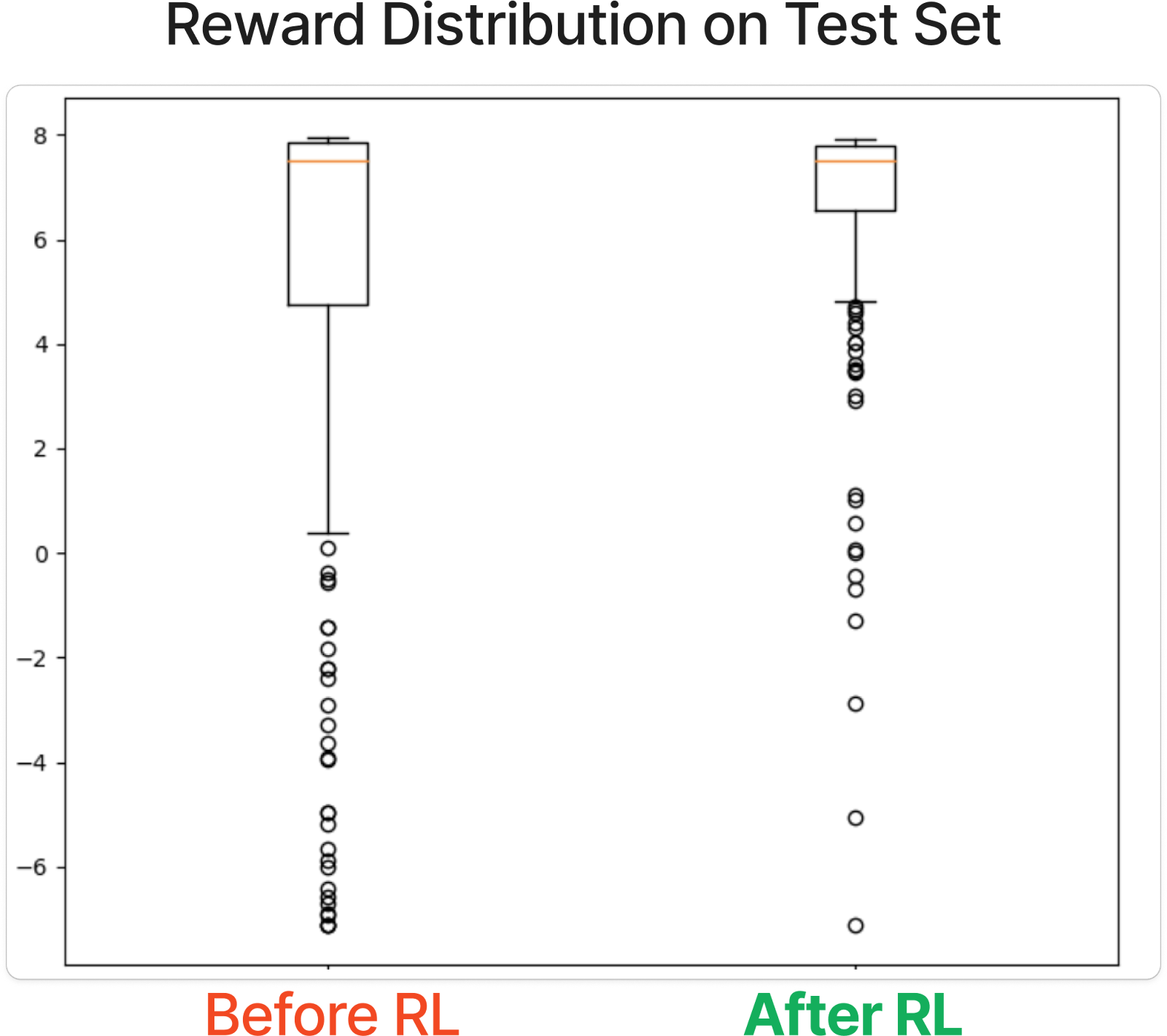
We see statistically significant changes in rewards from before (SFT only) and after alignment via RL
This means that the final SAWYER model, post RL, seems to be getting higher rewards, more consistently.
Reinforcement learning doesn’t help with everything though. For example, we can’t expect a model that received more rewards for answering in a way that humans prefer to be “smarter”. I ran these models against some well known benchmarks (below I’m showing truthful_qa and mmlu[world_religions]) and they got basically the same accuracy score:
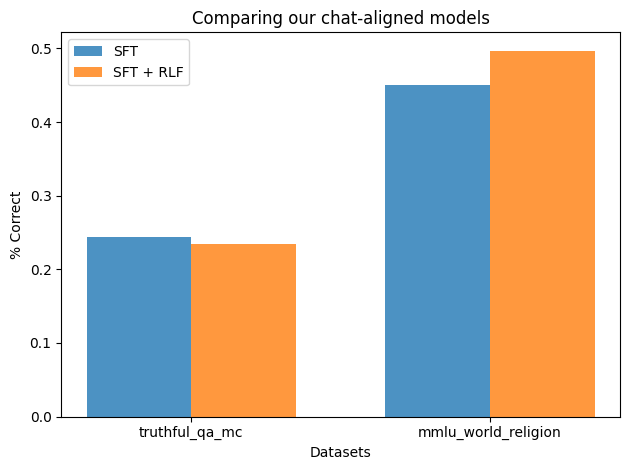
Our SFT and SFT + RLF models perform basically at the same level on tasks where the model needs to respond accurately and style is irrelevant (no chain of thought was applied here, I simply asked the model to answer a question directly)
I wasn’t expecting SAWYER to knock these benchmarks out of the park by any means, I just wanted to show the difference between what RL can and cannot help with. Aligning a model to chat factually and conversationally involves several steps and each step comes with caveats and nuances. Navigating these waters is challenging without step by step guidance and that is exactly what I will be providing at my upcoming workshop!
Conclusion
The exploration of Reinforcement Learning from Feedback (RLF) as a means to fine-tune Large Language Models (LLMs) towards specific behavioral goals—such as conversational attitudes, neutrality, or diversity—represents a significant leap forward in our quest to make AI more adaptable and responsive to human needs.
Through case studies like SAWYER, we can see firsthand the potential of SFT and RL to transform a pre-trained model into a more engaging and conversational agent. The process, involving a blend of supervised fine-tuning and reinforcement learning, underscores the complexity of aligning AI with nuanced human qualities. The results, while encouraging, also highlight the inherent limitations of current methodologies. While RL can guide models to interact in more human-like ways, it does not inherently increase their factual accuracy or understanding of the world.
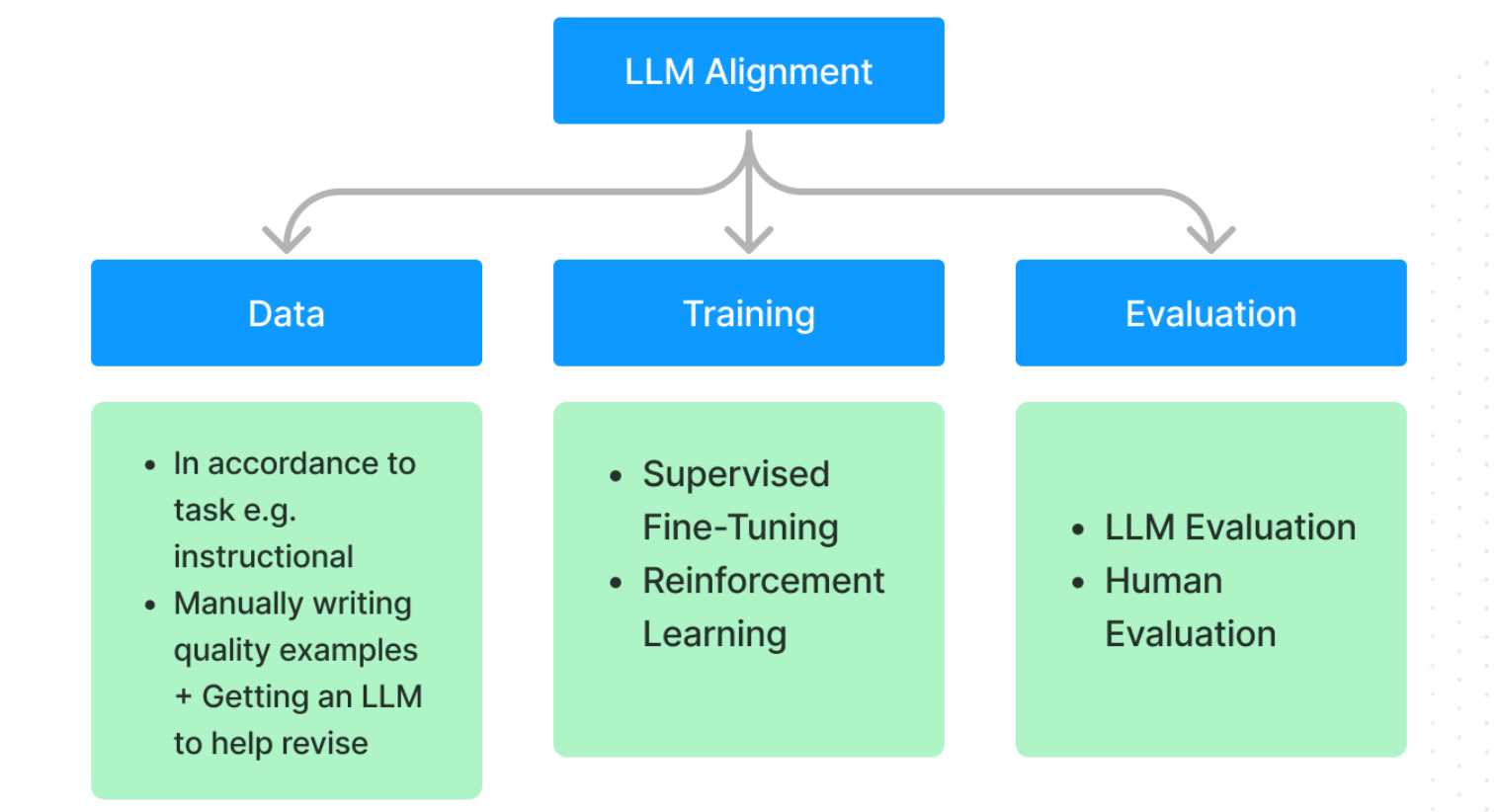
An overview of the three elements of LLM alignment
The journey of aligning AI with human expectations is ongoing. The successes and limitations of using RL from Feedback signal that while we can nudge AI towards more human-like interactions, the end goal—creating AI that truly understands and reflects human values, humor, and ethics—remains a challenging frontier. As we move forward, it is crucial to continue refining our approaches, questioning our objectives, and considering the broader implications of our quest to create AI that is not just aligned, but aligned to what end. The future of AI alignment is promising, yet it demands our thoughtful consideration, creativity, and, most importantly, our unwavering commitment to ethical principles.
For more on:
Why we are using PPO over DPO
Evaluating SAWYER’s capabilities
Tips and techniques I used to fine-tune SAWYER on a single GPU on Colab
How to properly fine-tune a reward mechanism
How PPO can help set us up for more longer term success than DPO can
Why higher rewards isn’t always a good thing
SAWYER’s opinions on poetry
And much more, come to our workshop at ODSC East in April! See you there.