- AI Office Hours
- Posts
- Probing LLMs for a World Model
Probing LLMs for a World Model
Sinan Ozdemir
April 25, 2024

There are active debates over whether LLMs are just memorizing vast amounts of statistics or if they can learn a more cohesive representation of the world whose language they model. Some have found evidence for the latter by analyzing the learned representations of datasets and even go so far as to discover that LLMs can learn linear representations of space and time (arxiv.org/abs/2310.02207).
As part of the 2nd edition of my latest LLM book (coming out later this year) one idea I wanted to add as a net new section aimed at recreating some of the work done in this paper by looking at a dataset comes from a paper entitled “A cross-verified database of notable people, 3500 BC-2018 AD” claiming to build a “comprehensive and accurate database of notable individuals”; just what we need to probe some LLMs on their ability to retain information about notable individuals they read about on the web.

I’m lucky to live in an age where open data for so many things exist: doi.org/10.1038/s41597-022-01369-4
Our steps to conduct the probe will be:
Design a prompt. At its simplest we will just say the name of the individual - like “Albert Einstein”
Instigate a forward pass of our LLM and grab embeddings from the middle layer and the final layer of our LLM’s hidden states.
For auto-encoding models like BERT, we will grab the reserved CLS token’s embedding and for auto-regressive models like Llama or Mistral, we will grab the embedding of the final token.
Use those token embeddings as inputs to a linear regression problem where we attempt to fit to three fields of the dataset plus a control fourth:
birth - the birth year of the individual
death - the death year of the individual (we filter to only use people who have died so this value is filled)
wiki_readers_2015_2018 - average per year number of page views in all Wikipedia editions (information retrieved in 2015–2018). We will use this as a weak signal to the notoriety level of the individual
random gibberish - just np.random.rand(len(dataset)). We will use this as a control as we should not be able to see any prediction signal
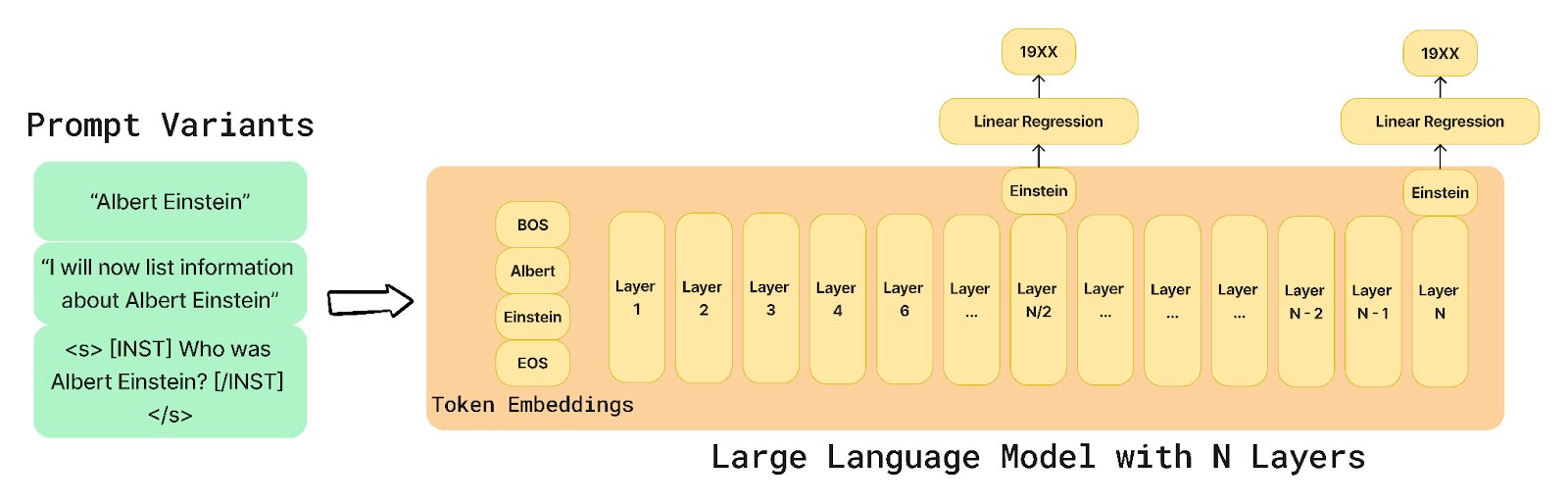
Probing gives us a way to understand how much information is locked away with the parameters of a model and whether or not we can extract that information through external processes. We place classifiers or regression layers in our case on top of hidden states and attempt to extract information like the birth year of the person we stated in the original prompt.
The goal of probing is not to act in place of an evaluation for a task but rather as an evaluation of a model as a whole in particular domains. The dataset I chose for this represents a relatively “generic” task - remember information it has read.
Probing Results
For every model we are going to probe we probe the first, middle, and ending layer’s final token embedding to regress to our four columns. The next figure shows an example of probing Llama 2 13b’s middle layer. Our birth year and death year probes perform surprisingly strongly; an RMSE of 80 years and R2 of over .5 is not the worst linear regressor I’ve trained, especially considering the scale of our data.
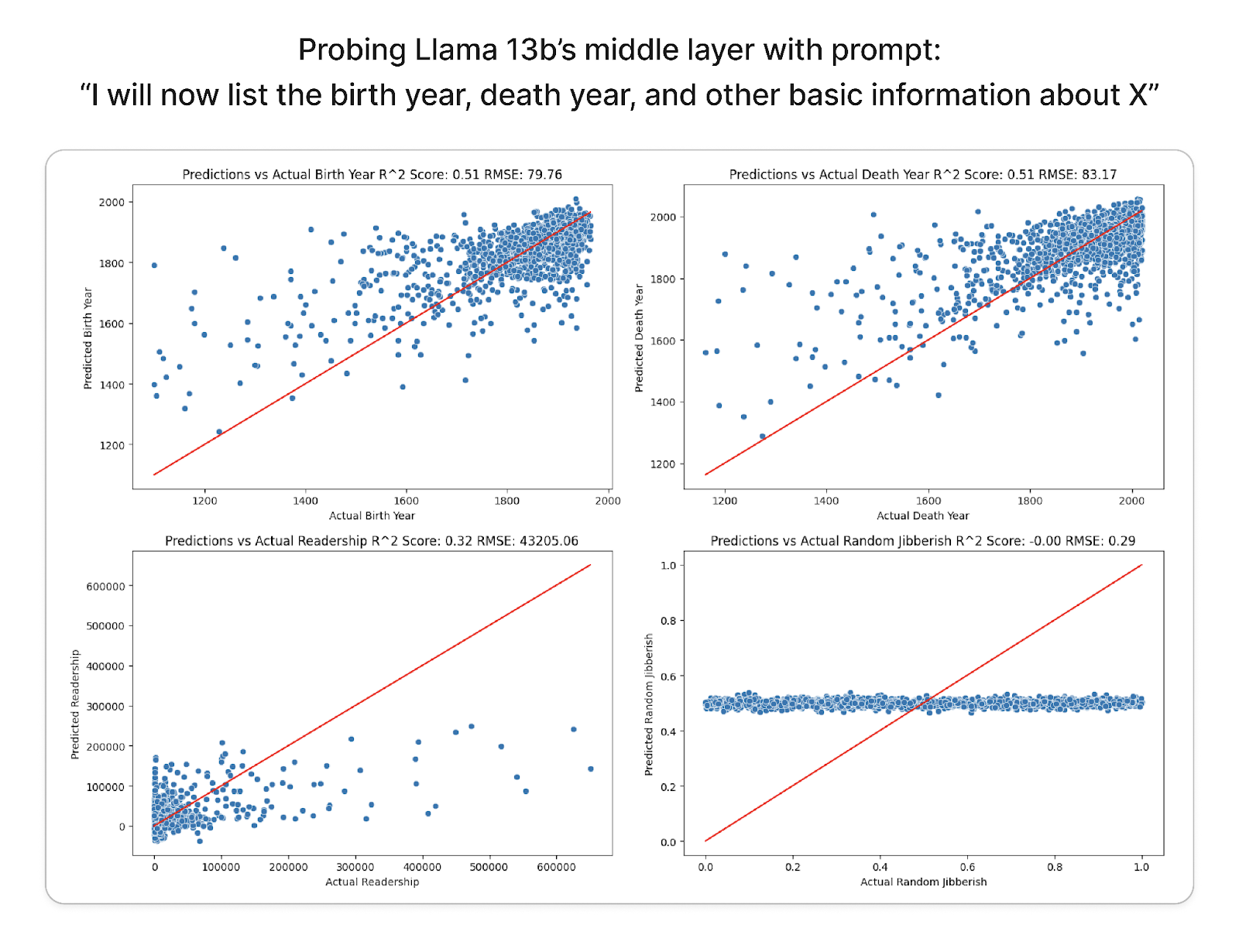
An example of probing the middle layer of a Llama 13b model with a constructed prompt. Our birth (top left) and death (top right) probes perform relatively well (R2 of above .5) while readership (bottom left) performs less well (R2 of .32) and our gibberish regression model performs poorly as expected (R2 of 0).
The above figure shows a smattering of models I probed by averaging the R2 achieved by a linear regression on the birth year against the embeddings from the middle and the final layer. The smaller four bars represent auto-encoding BERT models with far fewer parameters than Llama, SAWYER (a chat aligned version of Llama 2 I made), and Mistral v 0.1 and 0.2

Across 15 models, we see a wide range of R ^ 2 scores. BERT models, despite having the lowest scores, also have far fewer parameters, making them perhaps more efficient at storing information.
A couple of notable takeaways:
BERT base multilingual out performed BERT large English showing how the data that LLMs are pre-trained on matters
Mistral v0.2 as a 7B model performs as well as the Llama 2 13b models showing how parameter size is not everything
Llama 13B non instruct performed better when given a structured prompt (“basic information about X” vs simply “X”) showing how prompting can drastically alter the amount of information being retrieved
Are any of these “good” predictors of birth and death year? No absolutely not but that’s not the point. The point is to evaluate a model’s ability to encode and retrieve pre-trained knowledge. Moreover, even though our BERT models performed much worse, remember that A. they are several years older than the other models tested and B. They are ~72x smaller than the Llama 13B models and ~40x smaller than the 7B models.
The next bar graph shows the efficiency of three models measured by the number of parameters needed to achieve a single R2 value so lower means more efficient. BERT takes the cake for being able to retain the information much more efficiently, most likely due to the nature of its auto-encoding language modeling architecture and pre-training.
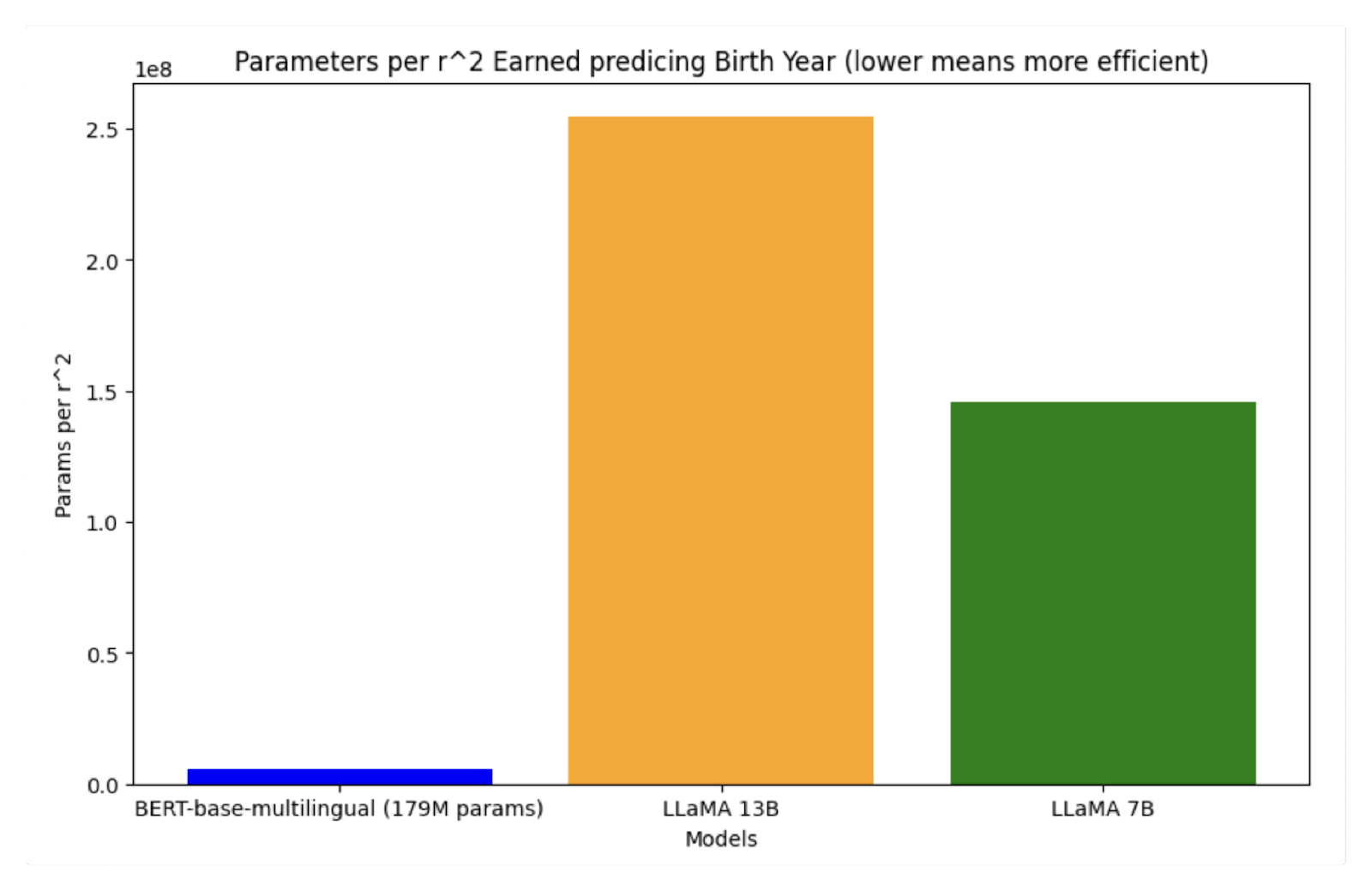
Between, BERT, Llama 2 13b, and Llama 2 7b, the number of parameters it takes to achieve the R2 in our probe can indicate the efficiency of the model’s ability to encode information. BERT requires far fewer parameters than Llama 2 to extract encoded information but would require more pre-training on recent data to become on par with the Llama 2 model’s performance
For a second probe, I ran the GSM8K testing data through five models and built similar probes to the actual answer of the problem and below we can see our results.

Probing 6 models on the GSM 8K benchmark by taking the final token of the input world problem and regressing to the actual answer.
It seems that Mistral v0.1 and v0.2 models have more retrievable encoded knowledge than the Llama models when it comes to mathematical word problems making them potential prime candidates for fine-tuning tasks related to math and logic.
Check out the raw code for the Llama 3 Probe here: https://colab.research.google.com/drive/1e1d9fATVjVun-_tPj4vS_DSTGaIfxs01?usp=sharing I’m still prettifying everything 😀