- AI Office Hours
- Posts
- (Re-) Ranking RAG Solutions

In August of 2022, mere months before ChatGPT made it’s world debut, I wrote a post on medium[1] about using auto-encoding LLMs like BERT to embed and retrieve documents from a vector database and then return responses to a query using information from that document. Sound familiar? I was describing a simplified version of Retrieval-Augmented Generation (RAG) inspired by a paper[2] in 2020. My version used two types of auto-encoding LLMs - one to retrieve and the other to “generate” a response by selecting the best subset of the document that answered the question (I know that’s not actual LLM text generation, but I wanted to use something open source and it was 2022).
Auto-encoding LLMs are models that cannot generate text token by token like the “Generative AI” models - ChatGPT, Claude, Llama, or virtually any LLM on the market today - but rather models who’s sole purpose is to read quickly and efficiently at much smaller sizes. To put that size difference in perspective, a case study in my book has a 70M parameter DistilBERT model beating ChatGPT (2,500x bigger parameter-wise) in a head to head fine-tuning classification test.
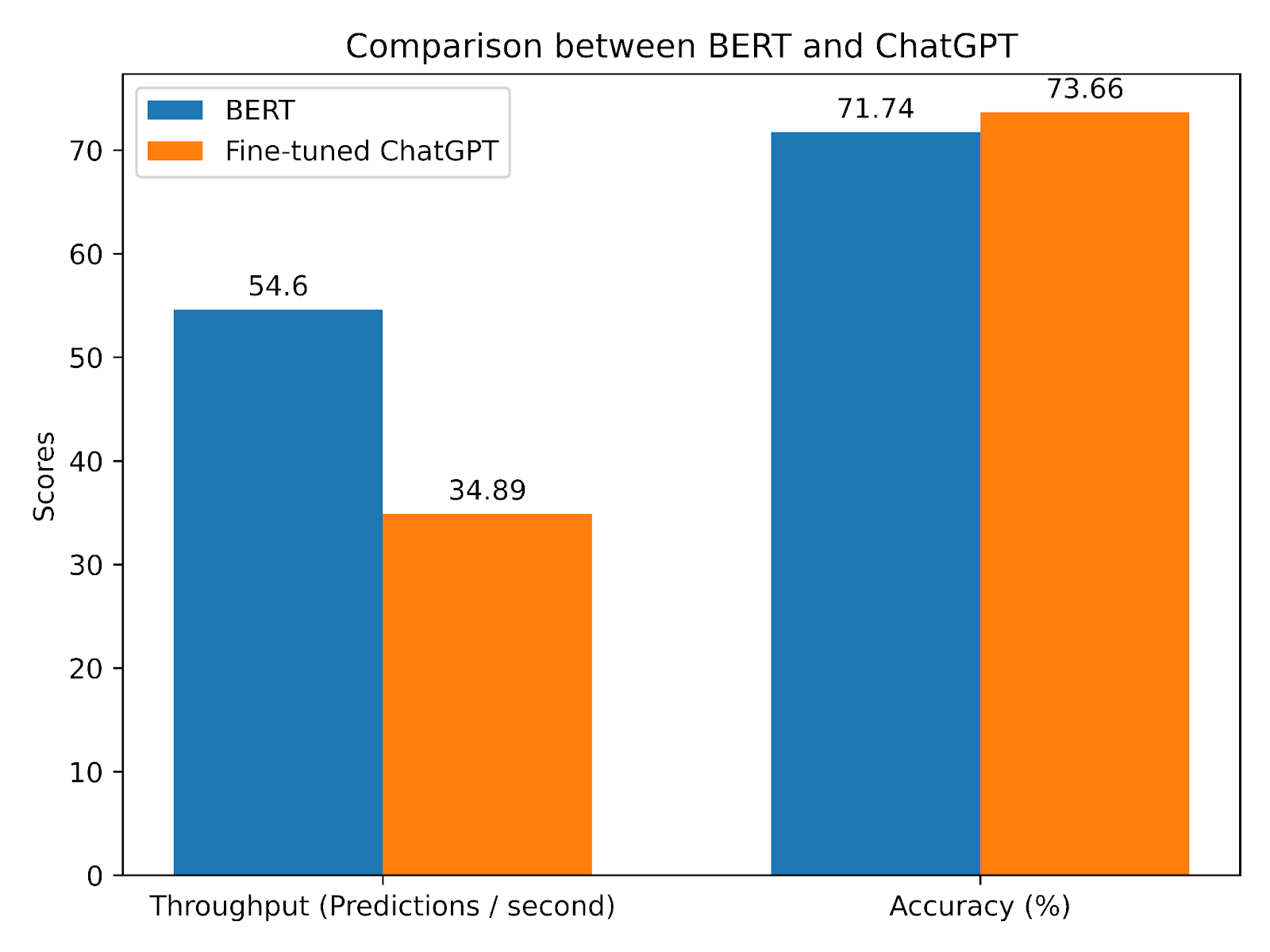
Case study from my book: DistilBERT (70M params) performing at a similar level as GPT 3.5 (175B params) on the same training data (https://hf.co/datasets/app_reviews) while being nearly twice as fast as GPT 3.5. Size isn’t everything
I’ve been both fascinated and disappointed in the field of auto-encoding models in recent years. So few companies seem to want to innovate on non-generative LLMs so when a use-case like RAG comes up where a huge chunk of that pipeline involves reading / retrieval i.e. not generating anything, I get excited.
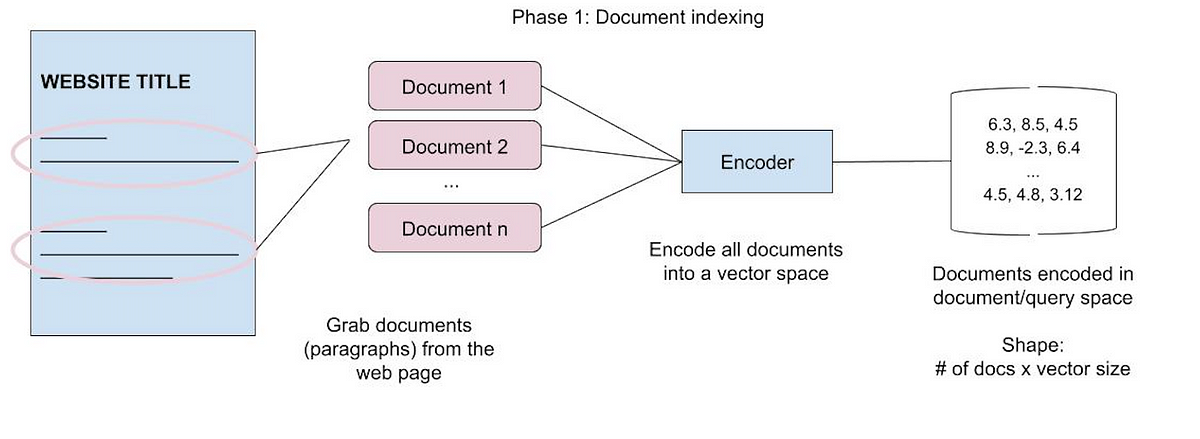
RAG can be broken down into three main steps (these figures are from my 2022 post but still are relevant):
Indexing documents - Using an embedding system to transform raw text into vectors and storing them in a database

Retrieving documents - Using (usually) the same embedding system to embed a query and using a vector similarity metric (like cosine similarity) to find the most relevant document

Generating a response - Using an LLM to create a raw text response to a user’s query using information in the document (yes I know there’s a typo in the figure, 2022 me messed up).

One of the main limitations of RAG systems is the quality of the retrieved document ranking. Cosine similarity between embeddings can only go so far in terms of matching queries to documents. This can be quantified by measuring how often an input query gets matched to the correct document which we will refer to as the top result accuracy of a RAG system, namely that the #1 closest retrieved document is in the fact the correct document that can answer the query. This post will go over an unsung hero in RAG that aims to maximize the effectiveness of this document ranking - the re-ranker.
Re-ranking Documents
At it’s core, a re-ranker is yet another LLM who’s job it is to take in a small amount (usually 10-50) of documents and the original query and rank the documents from most to least relevant. That sounds exactly like basic cosine retrieval because, well, it is the same result - a list of ranked documents.
How the re-ranking LLM does this is where things get different. Re-ranking happens on a much smaller scale than basic retrieval using cosine similarity from a vector DB because re-rankers’ architectures (often cross-encoders) are often more memory consumptive and slower but yield more precise results. They are considered an optional step between retrieval and generation.
Let’s look at a quick case study - a chatbot meant to help people navigate questions about Social Security.
Borrowing Government Data
Don’t worry, no one’s getting on a watch list for reading this. I’m taking just over 100 FAQs from https://faq.ssa.gov with corresponding help articles and using this as my data for this example. By the way, the full case study can be found at my O’Reilly RAG course[3] .

Our data for this case study: pre-written FAQs about America’s Social Security system
I will use OpenAI’s text-embedding-3-small model to do all document embeddings and Pinecone for my vector database. If you follow the code in [3] (namely the retrieval / generation notebooks), I will simply embed all FAQs and store them (along with the url and raw text) in a vector database for retrieval. I didn’t want to use a well known benchmark here because frankly I already think most LLM benchmarks are unhelpful to the average person and I grow increasingly worried that companies will want to simply overfit to these benchmarks to get market hype so I try to think of simple yet relatable non-benchmark examples.
Now we need to create some test data so we can start to see how well our system is performing.
Generating Synthetic Test Data
Grain of salt alert! We are going to ask GPT-4 to generate some potential questions to test our retrieval against. Synthetic data generation is a new sub-genre of generative tasks and one with consequential downstream effects. The test data we use here will inform us as to how well our chatbot is retrieving information and therefore is a measure of how well our bot can perform. My point here is that I will be using the below prompt to generate test data but I cannot actually read the non-english examples and vet them myself so I am taking the questions generated by GPT-4 here with a grain of salt.
I am designing a chatbot to use this document as information to our users.
Please write 10 questions that an average person not educated in this social security system might ask that can definitely be answered using information using the provided document.
Try to ask in a way that's confusing to really test our system's knowledge but still fair.
I need 5 in English, 2 in Spanish, 2 in Chinese, and 1 in French in that order.
Use this format to output:
Document: A given document to make questions from
JSON: ["english question 1", "english question 2", "english question 3", ... "spanish question 1", "spanish question 2", ..., "french question 1"]
###
Document: {document}
JSON:
>>>
[('english',
'How do I start the process for getting disability benefits from Social Security?'),
..
('spanish', '¿Cómo solicito beneficios por discapacidad del Seguro Social?'),
..
('chinese', '我不在美国居住,我可以申请社会保障残疾福利吗?'),
..
('french',
"Comment puis-je contacter mon bureau de sécurité sociale local pour des prestations d'invalidité?")]With all that, let’s look at our baseline results of just using OpenAI’s embedder and pinecone’s basic retrieval (just cosine similarity).
Baseline Results
For the 220 questions (10 per a 20% sample of our scraped urls) and for each language I generated data in, I broke it up and calculated two items:
the % of times the expected document was even in the list of 10 retrieved documents from Pinecone
The % of times the expected document was the top document in the list (will always less than or equal to the first number)

OpenAI embeddings alone are a decent showing with English performing the worst tied with Spanish at 82% top result accuracy.
Using OpenAI’s embeddings alone gives us about a 84% accuracy overall (weighted by language) of the synthetic test set. Not all languages were able to grab the document at all from Pinecone. To raise that number, we could grab more documents or use a different / fine-tuned embedder. Both great things to test, but not the main point of this post.
Making Retrieved Documents better with re-rankers
We finally arrive at the crux of this post. Once we retrieve the documents from our vector database, you can pass it along to a generative AI and call it a day. But with re-ranking systems and just 5-10 more lines of code (not a hyperbole, check out the Github[3] ), we can re-sort those documents from Pinecone to try and surface the actual relevant document to the top of the list. If we can consistently do this, we can pass fewer documents to our final RAG generation prompt resulting in a tighter, faster, and cheaper integration.
I evaluated two re-ranking systems for this:
Cohere’s v3 multilingual re-ranker - likely the largest company providing a marketable solution to the document re-ranking problem
Pongo’s semantic filter - one of the few small companies innovating in this space
Both of them work in a really simple way: provide a query and raw documents (not the OpenAI embeddings, they don’t matter to the re-ranker) and get back an ordered list of documents from most to least relevant. The test is simple - add this re-ranking step to the 10 retrieved documents from Pinecone. We will still be limited by the relevant document actually existing in the original 10, but we will be comparing Cohere and Pongo against simply using no re-ranking whatsoever.
Final Results
Everyone’s RAG system is different and your data will be different. For the data outlined above, our final results can be summarized as follows:
Both Cohere and Pongo improved top result accuracy from 84% to ~90% (~7% increase in performance).
Both models slowed the system down (not seen in the graph but both systems more than doubled the time to the testing process). This makes sense because we are actively performing a secondary LLM action.
Cohere’s model (being explicitly trained for multilingual use-cases) outperformed Pongo on Chinese, French, and Spanish.
Pongo beat Cohere on English examples (which represented 50% of the testing set).
Both Pongo and Cohere made our retrieval rankings better with ~5 lines of added code!
Overall, adding re-ranking to a system can take mere minutes to code up and as long as you have a proper testing set and a way to run tests automatically, there is no reason you cannot test your RAG systems against these re-rankers to see if they will have a net benefit on the retrieval accuracy.
Happy re-ranking!
References
[1] My August 2022 post on RAG:
[2] The Original RAG Paper:
[3] My current RAG class materials: